Spark快速入门-3-Spark的算子总结

Spark的算子的分类
- Transformation 变换/转换算子:这类算子操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。这种变换并不触发提交作业,完成作业中间过程处理。
- Action 行动算子:这类算子会触发 SparkContext 提交 Job 作业,并将数据输出 Spark 系统。
Transformation算子
Value数据类型的Transformation算子
- 输入与输出一对一
map算子,将原来 RDD 的每个数据项通过 map 中的自定义函数 f 映射转变为一个新的元素。
import org.apache.spark.{SparkConf, SparkContext}/*** @author Yezhiwei* @date 18/1/12*/object OperatorLearn extends App {val conf = new SparkConf().setAppName("OperatorLearn").setMaster("local")val sc = new SparkContext(conf)// mapval animal = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"))println(animal.map(_.length).collect.foreach(println))sc.stop()}// 输出36638() // 不知道为什么为多出一个来

图中每个方框表示一个 RDD 分区,左侧的分区经过自定义函数 f:T->U 映射为右侧的新 RDD 分区。但是,实际只有等到 Action 算子触发后,这个 f 函数才会和其他函数在一个 stage 中对数据进行运算。
flatMap算子,将原来 RDD 中的每个元素通过函数 f 转换为新的元素,并将生成的 RDD 的每个集合中的元素合并为一个集合。
println(animal.flatMap(x => List(x, x.length)).collect.foreach(print))// 输出, 最后多出个()dog3salmon6salmon6rat3elephant8()

上图表示 RDD 的一个分区,进行 flatMap 函数操作,flatMap 中传入的函数为 f:T->U,T 和 U 可以是任意的数据类型。将分区中的数据通过自定义函数 f 转换为新的数据。外部大方框可以认为是一个 RDD 分区,小方框代表一个集合。
mapPartitions算子,函数获取到每个分区的迭代器,在函数中通过这个分区整体的迭代器对整个分区的元素进行操作。
// mapPartitionsprintln("=" * 10 + "mapPartitions" + "=" * 10)println(animal.mapPartitions(iter => iter.filter(_.length > 3)).collect.foreach(println))// 输出salmonsalmonelephant
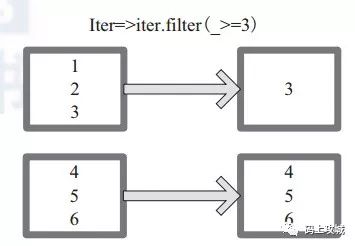
上图中,通过函数 f (iter)=>iter.f ilter(_>=3) 对分区中所有数据进行过滤,数据大于和等于 3 的数据保留。
glom算子,glom 函数将每个分区形成一个数组。
// glomval a = sc.parallelize(1 to 10, 3)println(a.glom.collect.map{x => x.foreach(elem => print(elem + " ")); println})// 输出1 2 34 5 67 8 9 10[Lscala.runtime.BoxedUnit;@78f4cff3

上图中的方框代表一个分区。该图表示含有 V1、V2、V3 的分区通过函数 glom 形成一数组Array[(V1), (V2), (V3)]。
- 输入与输出多对一
union算子,使用 union 函数时需要保证两个 RDD 元素的数据类型相同,返回的 RDD 数据类型和被合并的 RDD 元素数据类型相同,并不进行去重操作,保存所有元素。如果想去重可以使用 distinct()。++ 符号相当于 union 函数操作。
// unionval felidae = sc.parallelize(List("cat", "tiger"))val zoo = animal ++ felidaeprintln(zoo.collect.foreach(println))// 输出dogsalmonsalmonratelephantcattiger()

上图中左侧大方框代表两个 RDD,大方框内的小方框代表 RDD 的分区。右侧大方框代表合并后的 RDD,大方框内的小方框代表分区。含有V1、V2、U1、U2、U3、U4 的 RDD 和含有V1、V8、U5、U6、U7、U8的 RDD 合并所有元素形成一个 RDD。V1、V1、V2、V8形成一个分区,U1、U2、U3、U4、U5、U6、U7、U8形成一个分区。
cartesian(笛卡尔)算子,对两个 RDD 内的所有元素进行笛卡尔积操作。
// cartesianval x = sc.parallelize(List(1,2,3,4,5))val y = sc.parallelize(List(6,7,8,9,10))val carRDD = x.cartesian(y)println(carRDD.collect.foreach(elem => elem match {case (x, y) => println(x + " " + y)}))// 输出1 61 71 81 91 102 62 72 82 92 103 63 73 83 93 104 64 74 84 94 105 65 75 85 95 10()

上图中左侧大方框代表两个 RDD,大方框内的小方框代表 RDD 的分区。右侧大方框代表合并后的 RDD,大方框内的小方框代表分区。图中的大方框代表 RDD,大方框中的小方框代表 RDD 分区。例如:V1 和另一个 RDD 中的 W1、 W2、 Q5 进行笛卡尔积运算形成 (V1,W1)、(V1,W2)、 (V1,Q5)。
- 输入与输出多对多
grouBy算子,将元素通过函数生成相应的 Key,数据就转化为 Key-Value 格式,之后将 Key 相同的元素分为一组。
val a = sc.parallelize(1 to 10, 3)val groupByRDD = a.groupBy(x => if (x % 2 == 0) "even" else "odd")// Array[(String, Seq[Int])] = Array((even,ArrayBuffer(2, 4, 6, 8)), (odd,ArrayBuffer(1, 3, 5, 7, 9)))groupByRDD.collect.map(elem => elem match {case (x: String, y: Iterable[Int]) => println(x.mkString + " : " + y.mkString(", "))case _ => "..."})// 输出even : 2, 4, 6, 8, 10odd : 1, 3, 5, 7, 9
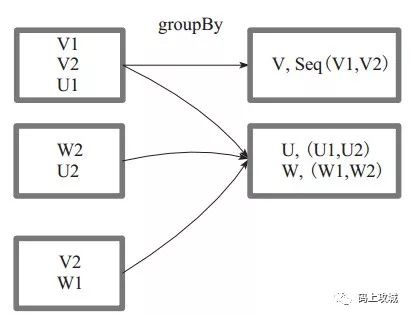
上图中方框代表一个 RDD 分区,相同 key 的元素合并到一个组。例如 V1 和 V2 合并为 V, Value 为 V1,V2。形成 V,Seq(V1,V2)。
- 输出为输入子集
filter算子, filter 函数功能是对元素进行过滤,对每个元素应用 f 函数,返回值为 true 的元素在 RDD 中保留,返回值为 false 的元素将被过滤掉。
// filterval evenRDD = a.filter(_ % 2 == 0)println(evenRDD.collect.mkString(", "))// 输出2, 4, 6, 8, 10

上图中每个方框代表一个 RDD 分区,T 可以是任意的类型。通过自定义的过滤函数 f,对每个数据项操作,将满足条件、返回结果为 true 的数据项保留。例如,过滤掉 V2 和 V3 保留了 V1,为区分命名为 V'1。
distinct算子,将RDD中的元素进行去重操作。
// distinctval animal = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"))println(animal.distinct.collect.mkString(", "))// 输出rat, elephant, dog, salmon

上图中的每个方框代表一个 RDD 分区,通过 distinct 函数,将数据去重。 例如,重复数据V1、 V1去重后只保留一份V1。
subtract算子,相当于进行集合的差操作,RDD 1去除RDD 1和RDD 2交集中的所有元素。
val a = sc.parallelize(1 to 9, 3)val b = sc.parallelize(1 to 3, 3)val c = a.subtract(b)println(c.collect.mkString(", "))// 输出6, 9, 4, 7, 5, 8

上图中左侧的大方框代表两个 RDD,大方框内的小方框代表 RDD 的分区。 右侧大方框代表合并后的 RDD,大方框内的小方框代表分区。 V1 在两个RDD 中均有,根据差集运算规则,新 RDD 不保留,V2 在第一个 RDD 有,第二个 RDD 没有,则在新 RDD 元素中包含 V2。
sample算子,将 RDD 这个集合内的元素进行采样,获取所有元素的子集。用户可以设定是否有放回的抽样、百分比、随机种子,进而决定采样方式。
// sampleprintln(a.sample(false, 0.5, 10).collect.mkString(", "))println(a.sample(true, 0.5, 10).collect.mkString(", "))// 输出4, 5, 8, 92, 4, 8, 8

上图中的每个方框是一个 RDD 分区。通过 sample 函数,采样 50% 的 数据。V1、V2、U1、U2、U3、U4 采样出数据 V1 和 U1、U2 形成新的 RDD。
takeSample算子,和上面的sample函数是一个原理,但是不使用相对比例采样,而是按设定的采样个数进行采样,同时返回结果不再是RDD,而是相当于对采样后的数据进行 collect(),返回结果的集合为单机的数组。
// takeSampleprintln(a.takeSample(false, 5, 10).mkString(", "))println(a.takeSample(true, 5, 10).mkString(", "))// 输出9, 5, 7, 6, 86, 8, 9, 5, 2
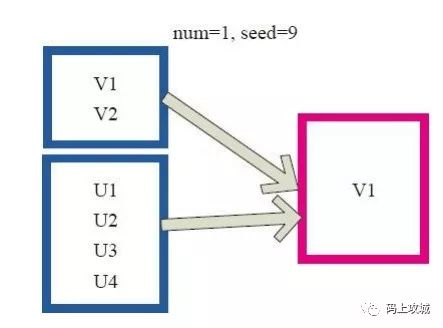
上图中左侧的方框代表分布式的各个节点上的分区,右侧方框代表单机上返回的结果数组。 通过 takeSample 对数据采样,设置为采样一份数据,返回结果为V1。
- Cache型
cache算子,这个方法也是个 Tranformation,当第一次遇到 Action 算子的时才会进行持久化将 RDD 元素从磁盘缓存到内存。在 Spark 中很多地方都会用到同一个 RDD, 按照常规的做法,每个地方遇到 Action 操作的时候都会对同一个算子计算多次,这样会造成效率低下的问题。相当于 persist(MEMORY_ONLY) 函数的功能。
// cacheval animal = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"))println(animal.getStorageLevel)val animalCache = animal.cacheprintln(animal.getStorageLevel)println(animalCache.getStorageLevel)println(animalCache.map(_.length).collect.foreach(println))println(animalCache.map(_.length).collect.foreach(println))// 输出StorageLevel(1 replicas)StorageLevel(memory, deserialized, 1 replicas)StorageLevel(memory, deserialized, 1 replicas)
persist算子
Key-Value数据类型的Transfromation算子
- 输入与输出一对一
mapValues算子,针对(Key, Value)型数据中的 Value 进行 Map 操作,而不对 Key 进行处理。
// mapValuesval lenAnimal = animal.map(x => (x.length, x))println(lenAnimal.mapValues("|" + _ + "|").collect.mkString(", "))// 输出(3,|dog|), (6,|salmon|), (6,|salmon|), (3,|rat|), (8,|elephant|)

上图中的方框代表 RDD 分区。a=>a+2 代表对 (V1,1) 这样的 Key Value 数据对,数据只对 Value 中的 1 进行加 2 操作,返回结果为 3。
- 对单个RDD或两个RDD聚集
单个RDD聚集
combineByKey算子
reduceByKey算子,只是两个值合并成一个值,比如叠加。
val animal = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"))val lenRDD = animal.map(x => (x.length, x))println(lenRDD.reduceByKey(_ + _).collect.mkString(", "))// 输出(6,salmonsalmon), (3,dograt), (8,elephant)

上图中的方框代表 RDD 分区。通过自定义函数 (A,B) => (A + B) 函数,将相同 key 的数据 (V1,2) 和 (V1,1) 的 value 相加运算,结果为( V1,3)。
partitionBy算子
两个RDD聚集
cogroup算子,将两个RDD进行协同划分。对在两个RDD中的Key-Value类型的元素,每个RDD相同Key的元素分别聚合为一个集合,并且返回两个RDD中对应Key的元素集合的迭代器。(K, (Iterable[V], Iterable[W]))其中,Key和Value,Value是两个RDD下相同Key的两个数据集合的迭代器所构成的元组。
val a = sc.parallelize(List(1, 2, 1, 3), 1)val b = a.map((_, "b"))val c = a.map((_, "c"))println(b.cogroup(c).collect.mkString(", "))// 输出(1,(CompactBuffer(b, b),CompactBuffer(c, c))), (3,(CompactBuffer(b),CompactBuffer(c))), (2,(CompactBuffer(b),CompactBuffer(c)))

上图中的大方框代表 RDD,大方框内的小方框代表 RDD 中的分区。 将RDD1中的数据(U1,1)、 (U1,2)和RDD2中的数据(U1,2)合并为(U1,((1,2),(2)))。
- 连接
join算子,对两个需要连接的 RDD 进行 cogroup函数操作,将相同 key 的数据能够放到一个分区,在 cogroup 操作之后形成的新 RDD 对每个key 下的元素进行笛卡尔积的操作,返回的结果再展平,对应 key 下的所有元组形成一个集合。最后返回 RDD[(K, (V, W))]。
val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)val b = a.keyBy(_.length)println(b.collect.mkString(", "))val c = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)val d = c.keyBy(_.length)println(d.collect.mkString(", "))println(b.join(d).collect.mkString(", "))// 输出(3,dog), (6,salmon), (6,salmon), (3,rat), (8,elephant)(3,dog), (3,cat), (3,gnu), (6,salmon), (6,rabbit), (6,turkey), (4,wolf), (4,bear), (3,bee)(6,(salmon,salmon)), (6,(salmon,rabbit)), (6,(salmon,turkey)), (6,(salmon,salmon)), (6,(salmon,rabbit)), (6,(salmon,turkey)), (3,(dog,dog)), (3,(dog,cat)), (3,(dog,gnu)), (3,(dog,bee)), (3,(rat,dog)), (3,(rat,cat)), (3,(rat,gnu)), (3,(rat,bee))

上图中是对两个 RDD 的 join 操作示意图。大方框代表 RDD,小方框代表 RDD 中的分区。函数对相同 key 的元素,如 V1 为 key 做连接后结果为 (V1,(1,1)) 和 (V1,(1,2))。
leftOutJoin 和 rightOutJoin算子,LeftOutJoin(左外连接)和 RightOutJoin(右外连接)相当于在 join 的基础上先判断一侧的RDD元素是否为空,如果为空,则填充为空。 如果不为空,则将数据进行连接运算,并返回结果。
// leftOuterJoinprintln(b.leftOuterJoin(d).collect.mkString(", "))// 输出(6,(salmon,Some(salmon))), (6,(salmon,Some(rabbit))), (6,(salmon,Some(turkey))), (6,(salmon,Some(salmon))), (6,(salmon,Some(rabbit))), (6,(salmon,Some(turkey))), (3,(dog,Some(dog))), (3,(dog,Some(cat))), (3,(dog,Some(gnu))), (3,(dog,Some(bee))), (3,(rat,Some(dog))), (3,(rat,Some(cat))), (3,(rat,Some(gnu))), (3,(rat,Some(bee))), (8,(elephant,None))// rightOuterJoinprintln(b.rightOuterJoin(d).collect.mkString(", "))// 输出(6,(Some(salmon),salmon)), (6,(Some(salmon),rabbit)), (6,(Some(salmon),turkey)), (6,(Some(salmon),salmon)), (6,(Some(salmon),rabbit)), (6,(Some(salmon),turkey)), (3,(Some(dog),dog)), (3,(Some(dog),cat)), (3,(Some(dog),gnu)), (3,(Some(dog),bee)), (3,(Some(rat),dog)), (3,(Some(rat),cat)), (3,(Some(rat),gnu)), (3,(Some(rat),bee)), (4,(None,wolf)), (4,(None,bear))
Action算子
- 无输出
foreach算子,通过自定义函数对每个数据项进行操作。对 RDD 中的每个元素都应用 f 函数操作,不返回 RDD 和 Array,而是返回Uint。

上图中表示自定义函数为 println(),控制台打印所有数据项。
- HDFS
saveAsTextFile算子,存储到 HDFS 的指定目录。
saveAsObjectFile算子
- Scala集合和数据类型
collect算子,相当于 toArray, toArray 已经过时不推荐使用, collect 将分布式的 RDD 返回为一个单机的 scala Array 数组。在这个数组上运用 scala 的函数式操作。

上图中左侧方框代表 RDD 分区,右侧方框代表单机内存中的数组。通过函数操作,将结果返回到 Driver 程序所在的节点,以数组形式存储。
collectAsMap算子,对(K,V)型的RDD数据返回一个单机HashMap。 对于重复K的RDD元素,后面的元素覆盖前面的元素。
// collectAsMapval a = sc.parallelize(List(1, 2, 1, 3), 1)val b = a.zip(a)println(b.collectAsMap.foreach(elem => elem match {case (k, v) => println(k + "->" + v)}))// 输出2->21->13->3()

上图中的左侧方框代表 RDD 分区,右侧方框代表单机数组。 数据通过collectAsMap 函数返回给 Driver 程序计算结果,结果以 HashMap 形式存储。
reduceByKeyLocally算子,实现的是先reduce再collectAsMap的功能,先对RDD的整体进行reduce操作,然后再收集所有结果返回为一个HashMap。
val a = sc.parallelize(List("dog", "cat", "owl", "gnu", "ant"), 2)val b = a.map(x => (x.length, x))b.reduceByKey(_ + _).collect
lookup算子,函数对(Key,Value)型的RDD操作,返回指定Key对应的元素形成的Seq。 这个函数处理优化的部分在于,如果这个RDD包含分区器,则只会对应处理K所在的分区,然后返回由(K,V)形成的Seq。 如果RDD不包含分区器,则需要对全RDD元素进行暴力扫描处理,搜索指定K对应的元素。
// lookupval a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)val b = a.map(x => (x.length, x))println(b.lookup(5).mkString(", "))// 输出tiger, eagle

上图中的左侧方框代表 RDD 分区,右侧方框代表 Seq,最后结果返回到Driver所在节点的应用中。
count算子,返回整个 RDD 的元素个数。

上图中,返回数据的个数为 5。一个方块代表一个 RDD 分区。
top算子,可返回最大的k个元素。相近函数,take返回最小的k个元素;takeOrdered返回最小的k个元素,并且在返回的数组中保持元素的顺序。
val c = sc.parallelize(Array(6, 9, 4, 7, 5, 8), 2)c.top(2)res28: Array[Int] = Array(9, 8)
reduce算子,函数相当于对RDD中的元素进行reduceLeft函数的操作。
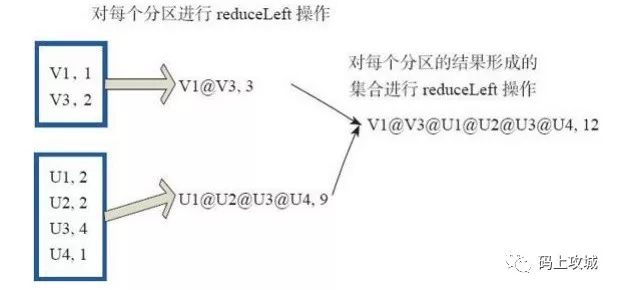
自定义函数如: f:(A,B)=>(A.1+"@"+B.1,A.2+B.2)
上图中的方框代表一个RDD分区,通过自定函数f将数据进行reduce运算。 最后的返回结果为V1@[1]V2U!@U2@U3@U4,12。
fold算子,fold和reduce的原理相同,但是与reduce不同,相当于每个reduce时,迭代器取的第一个元素是zeroValue。

fold(("V0@",2))( (A,B)=>(A.1+"@"+B.1,A.2+B.2))
上图中通过下面的自定义函数进行fold运算,图中的一个方框代表一个RDD分区。
aggregate算子,aggregate先对每个分区的所有元素进行 aggregate 操作,再对分区的结果进行fold操作。aggreagate 与 fold 和 reduce 的不同之处在于,aggregate 相当于采用归并的方式进行数据聚集,这种聚集是并行化的。 而在 fold 和 reduce 函数的运算过程中,每个分区中需要进行串行处理,每个分区串行计算完结果,结果再按之前的方式进行聚集,并返回最终聚集结果。
以上就是关于【Spark快速入门-3-Spark的算子总结】的解答,如需了解学校/赛事/课程动态,可至翰林教育官网获取更多信息。
往期文章阅读推荐:
准大一必看!如何利用暑假“抢跑”拿下高GPA?翰林预学班全攻略!


翰林AMC8视频课重磅上线!

国际竞赛真题资源免费领取






